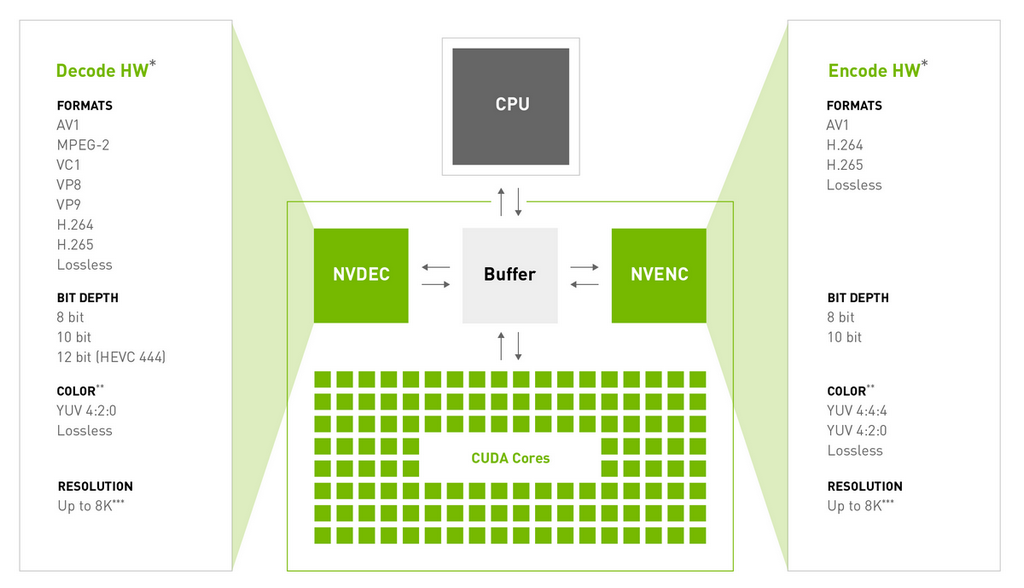
Udoskonalenie zabezpieczeń i poufne przetwarzanie danych
Dostawcy usług w chmurze (Cloud Service Providers – CSP), producenci samochodów, laboratoria krajowe, służba zdrowia, finanse oraz wiele innych branż i organizacji wymaga wysokiego poziomu bezpieczeństwa. Ogromne ilości wrażliwych danych są generowane, przechowywane i przetwarzane każdego dnia. Chociaż istnieją zaawansowane techniki szyfrowania do ochrony danych przechowywanych w pamięci masowej i przesyłanych przez sieć, istnieje obecnie duża luka w ochronie danych podczas ich przetwarzania lub używania. Nowa technologia poufnego przetwarzania danych wypełnia tę lukę, chroniąc dane i aplikacje oraz zapewniając większe bezpieczeństwo organizacjom zarządzającym danymi wrażliwymi i podlegającym państwowym regulacjom.
NVIDIA H100 zawiera szereg funkcji bezpieczeństwa, które ograniczają dostęp do zawartości GPU, zapewniając dostęp tylko upoważnionym podmiotom, zapewniając bezpieczne uruchamianie i możliwości uwierzytelniania oraz aktywnie monitorując ataki podczas działania systemu. Ponadto wyspecjalizowane, wbudowane procesory bezpieczeństwa, obsługa wielu typów i poziomów szyfrowania, chronione sprzętowo regiony pamięci, rejestry kontroli dostępu uprzywilejowanego, wbudowane czujniki i wiele innych funkcji zapewniają użytkownikom bezpieczne przetwarzanie danych.
H100 to pierwszy na świecie procesor graficzny obsługujący przetwarzanie poufne. Użytkownicy mogą chronić poufność i integralność swoich danych i używanych aplikacji, korzystając jednocześnie z niespotykanej akceleracji procesorów graficznych H100. H100 zapewnia szeroką gamę innych funkcji bezpieczeństwa w celu ochrony danych użytkownika, obrony przed atakami sprzętowymi i programowymi oraz lepszej izolacji i ochrony maszyn wirtualnych przed sobą w środowiskach zwirtualizowanych i MIG.
Główne cele wszechstronnych funkcji bezpieczeństwa GPU NVIDIA H100 obejmują:
- Ochrona i izolacja danych: Uniemożliwianie nieautoryzowanym podmiotom uzyskiwania dostępu do danych innego użytkownika, gdy podmiotem może być użytkownik, system operacyjny, hyperwizor lub oprogramowanie sprzętowe GPU.
- Ochrona zawartości: Uniemożliwianie nieautoryzowanym podmiotom uzyskiwania dostępu do chronionych treści przechowywanych lub przetwarzanych przez GPU.
- Ochrona przed uszkodzeniami fizycznymi: Zapobieganie fizycznym uszkodzeniom GPU, niezależnie od tego, czy są one spowodowane przez złośliwą osobę, czy przez przypadek.
Przetwarzanie poufne NVIDIA
Formalna definicja terminu Confidential Computing to „ochrona danych poprzez wykonywanie obliczeń w środowisku sprzętowym opartym o Trusted Execution Environment (TEE)”. Definicja jest niezależna od tego, gdzie dane są używane, czy to w chmurze, czy na urządzeniach użytkowników końcowych, czy gdzieś pomiędzy. Jest również niezależna od tego, który procesor chroni dane lub jaka technika ochrony jest stosowana. C3 (Confidential Computing Consortium) definiuje TEE jako „środowisko, które zapewnia poziom pewności dla trzech kluczowych właściwości – poufności danych, integralności danych i integralności kodu”.
Obecnie dane są często chronione w stanie spoczynku, podczas przechowywania i przesyłania przez sieć, ale nie są chronione przez system operacyjny/ hyperwizora podczas ich używania. Ten wymóg zaufania do systemu operacyjnego / hyperwizora pozostawia dużą lukę w ochronie danych i kodu dla użytkowników. Ponadto możliwość ochrony danych i kodu podczas ich używania jest ograniczona w konwencjonalnej infrastrukturze obliczeniowej. Organizacje, które przetwarzają dane wrażliwe, takie jak informacje umożliwiające identyfikację osób, dane finansowe i dotyczące zdrowia, lub które są zobowiązane do przestrzegania przepisów dotyczących lokalizacji danych, muszą na wszystkich etapach ograniczać zagrożenia, których celem jest poufność i integralność ich aplikacji, modeli i danych.
Dotychczas istniejące poufne rozwiązania obliczeniowe były oparte na CPU i były zbyt wolne dla zadań wymagających dużej mocy obliczeniowej, takich jak sztuczna inteligencja i HPC. Poufne przetwarzanie oparte na CPU generalnie zmniejsza wydajność systemu, co może mieć wpływ na produktywność lub być nieopłacalne w przypadku obciążeń związanych z przetwarzaniem danych wrażliwych na opóźnienia.
Dzięki NVIDIA CC, nowej funkcji bezpieczeństwa wprowadzonej w architekturze NVIDIA Hopper, H100 jest pierwszym na świecie procesorem graficznym, który może chronić poufność i integralność zarówno danych, jak i używanego kodu. H100 wprowadza akcelerację przetwarzania do świata poufnych obliczeń i rozszerza TEE CPU na GPU. H100 otwiera drzwi do wielu przypadków użycia, w których korzystanie ze współdzielonej infrastruktury (chmura, kolokacja, edge) nie było możliwe w przeszłości ze względu na konieczność ochrony danych i kodu podczas użytkowania oraz fakt, że poprzednie rozwiązania do przetwarzania poufnego są nie jest wystarczająco wydajny lub elastyczny dla wielu obciążeń.
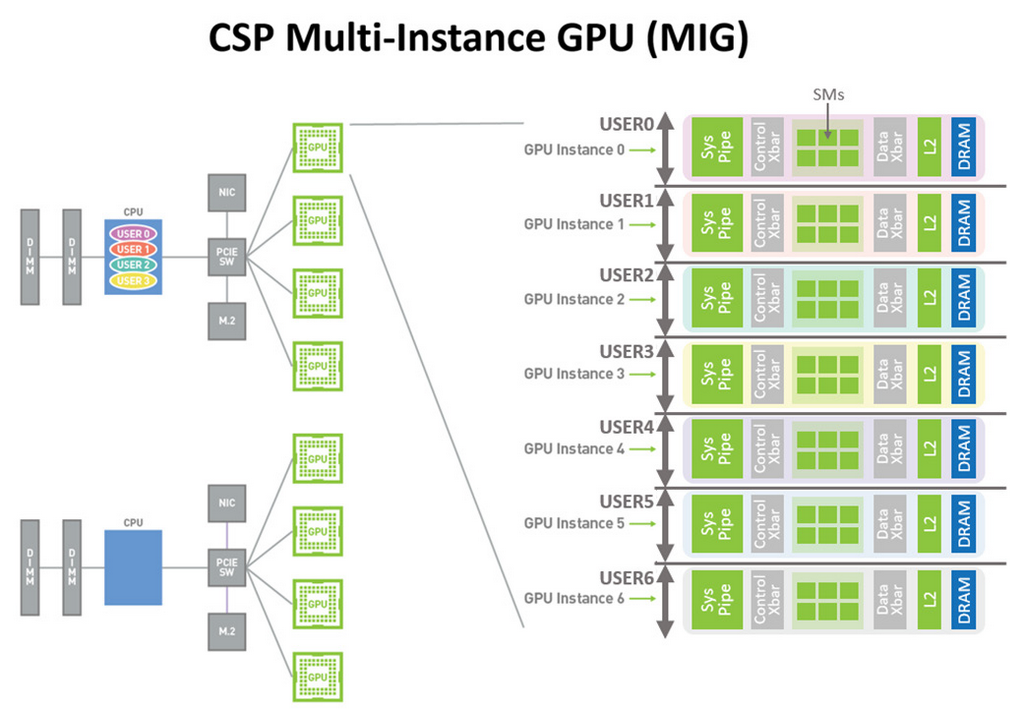
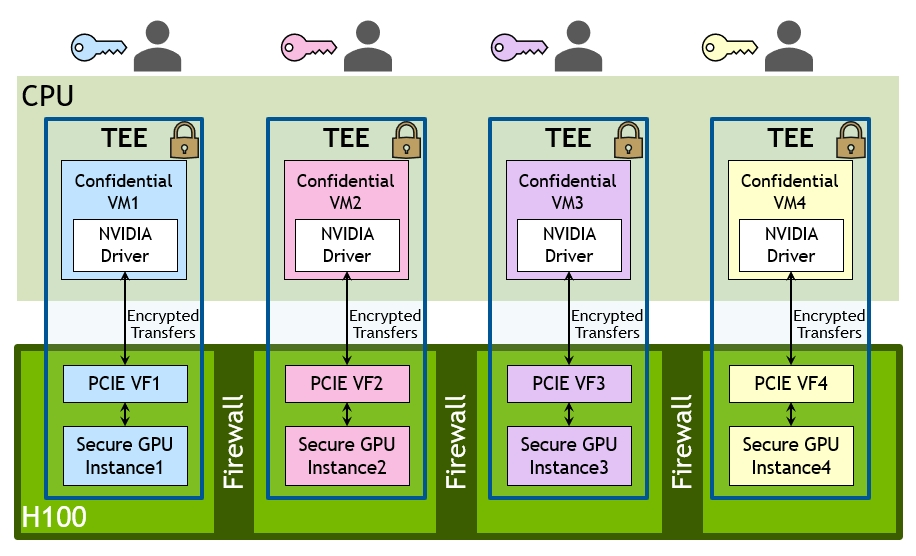
NVIDIA CC tworzy sprzętowe TEE, które zabezpiecza i izoluje całe obciążenie działające na pojedynczym GPU H100, wielu GPU H100 w węźle lub na indywidualnych zabezpieczonych instancjach Multi-Instance GPU (MIG). TEE ustanawia bezpieczny kanał między poufną maszyną wirtualną na GPU i jej odpowiednikiem w CPU.
TEE zapewnia dwa tryby działania:
1. Cały procesor graficzny jest przypisany wyłącznie do jednej maszyny wirtualnej (do jednej maszyny wirtualnej może być jednocześnie przypisanych wiele procesorów graficznych).
2. Procesor graficzny NVIDIA H100 jest podzielony na partycje i obsługuje wiele maszyn wirtualnych przy użyciu technologii MIG, umożliwiając poufne przetwarzanie wielu dzierżawców. Aplikacje akcelerowane przez GPU mogą działać bez zmian w TEE i nie muszą być partycjonowane ręcznie.
Użytkownicy mogą połączyć bogate portfolio i moc oprogramowania NVIDIA dla sztucznej inteligencji i HPC z bezpieczeństwem Hardware Root of Trust oferowanym przez NVIDIA CC, aby zapewnić bezpieczeństwo i ochronę danych na najniższym poziomie architektury GPU. Użytkownicy mogą uruchamiać i testować aplikacje w infrastrukturze współużytkowanej lub zdalnej i mieć pewność, że żadne nieautoryzowane podmioty, w tym hyperwizor, system operacyjny hosta, administrator systemu, właściciel infrastruktury lub ktokolwiek z fizycznym dostępem, nie będą mogły przeglądać ani modyfikować kodu i danych aplikacji, gdy są one używane w ramach TEE.
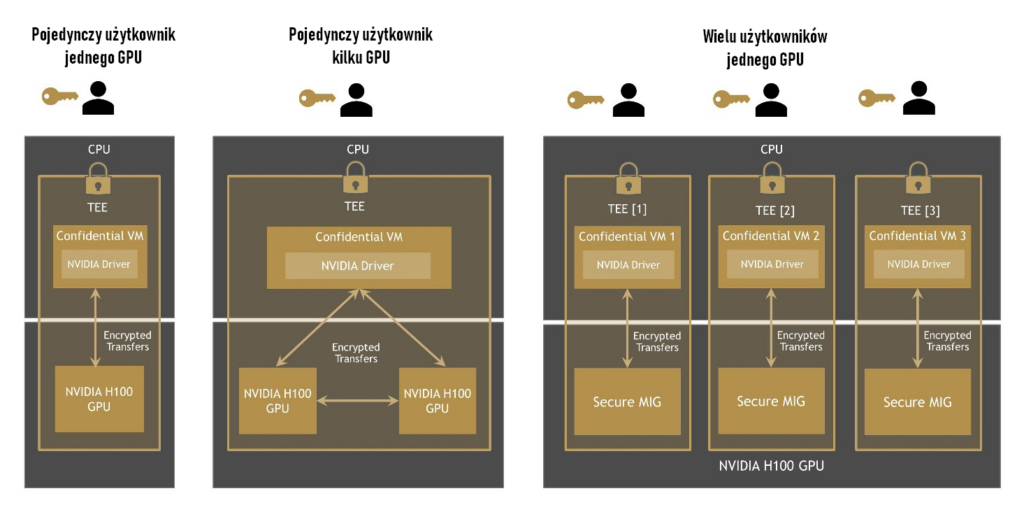
Poufne przetwarzanie danych w różnych przypadkach użycia
Możliwości przetwarzania poufnego w architekturze Hopper dodatkowo wzmacniają i przyspieszają bezpieczeństwo w przypadkach użycia wielostronnego przetwarzania opartego na współpracy, takich jak Federated Learning. Federated Learning w środowisku rozproszonym umożliwia wielu organizacjom współpracę w celu szkolenia lub oceny modeli AI bez konieczności udostępniania zastrzeżonych zestawów danych każdej grupy. Szkolenie na H100 gwarantuje, że dane i modele sztucznej inteligencji będą chronione przed nieautoryzowanym dostępem przez zagrożenia zewnętrzne lub wewnętrzne w każdej uczestniczącej witrynie, a każda witryna może zrozumieć i zatwierdzić oprogramowanie działające na swoich równorzędnych urządzeniach. Zwiększa to zaufanie do bezpiecznej współpracy i napędza postęp badań medycznych, przyspiesza opracowywanie leków, ogranicza oszustwa ubezpieczeniowe i finansowe oraz wiele innych aplikacji – przy jednoczesnym zachowaniu bezpieczeństwa, prywatności i zgodności z przepisami.
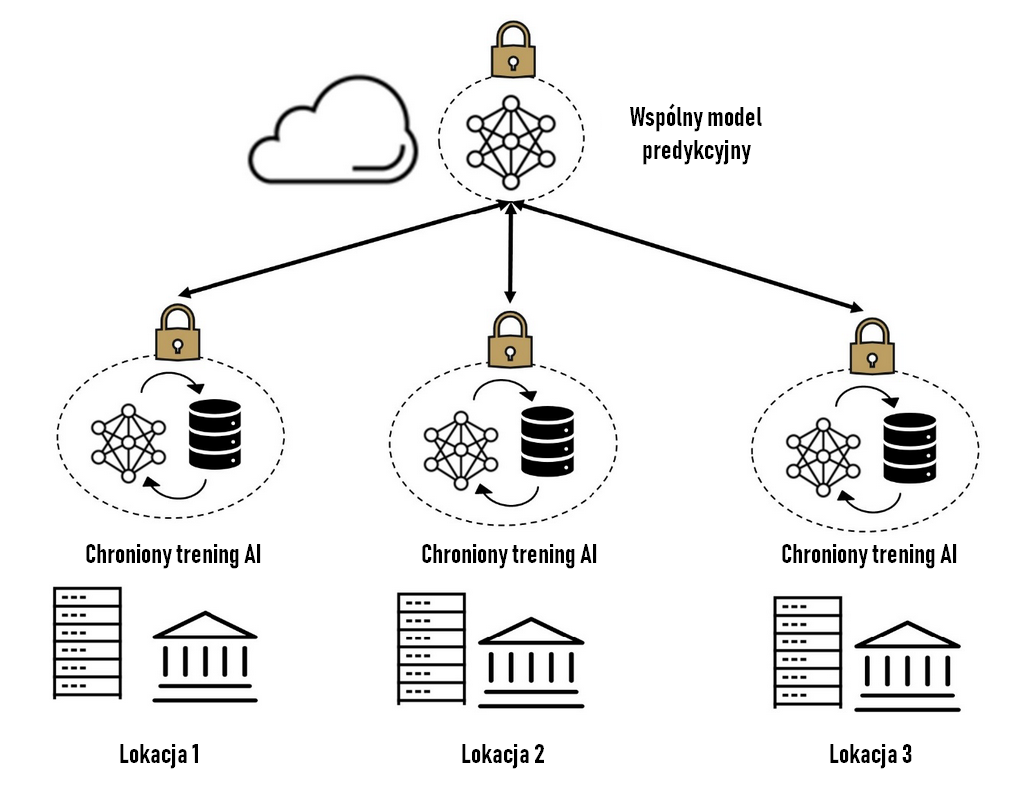
Poufne trenowanie sieci w środowisku rozproszonym
Chociaż architektura GPU NVIDIA Ampere obejmowała technologię bezpiecznego rozruchu, nie obsługiwała ona monitorowanego rozruchu, który jest wymagany do zachowania zgodności z zasadami przetwarzania poufnego. Bezpieczny rozruch to zestaw systemów sprzętowych i programowych, które zapewniają uruchomienie GPU ze znanego bezpiecznego stanu, zezwalając na uruchamianie tylko uwierzytelnionego oprogramowania układowego i mikrokodu, które zostały opracowane i sprawdzone przez firmę NVIDIA podczas uruchamiania GPU. Monitorowany rozruch to proces zbierania, bezpiecznego przechowywania i raportowania charakterystyk procesu rozruchu, który określa bezpieczny stan GPU. Atestacja i weryfikacja to sposoby porównywania pomiarów z wartościami odniesienia w celu zapewnienia, że urządzenie jest w oczekiwanym bezpiecznym stanie. NVIDIA zapewnia atestatorów, wartości referencyjne i podpisy adnotacji.
Proces wykorzystuje pomiary dostarczane przez monitorowany rozruch i porównuje je z wartościami referencyjnymi dostarczonymi przez firmę NVIDIA lub usługodawców w celu określenia czy system jest w stanie gotowym i bezpiecznym do rozpoczęcia działania na danych klienta. Po sprawdzeniu poprawności systemu klient może uruchamiać aplikacje tak, jakby uruchamiał tą samą aplikację w niechronionym środowisku obliczeniowym.
Implementacja przetwarzania poufnego NVIDIA
Jak widać na poniższym schemacie, lewa strona z wyłączoną funkcją NVIDIA CC przedstawia tradycyjną architekturę komputera PC, w której system operacyjny hosta i hyperwizor mają pełny dostęp do urządzeń, takich jak procesor graficzny. Prawa strona z NVIDIA CC On pokazuje pełną izolację maszyny wirtualnej od innych elementów.
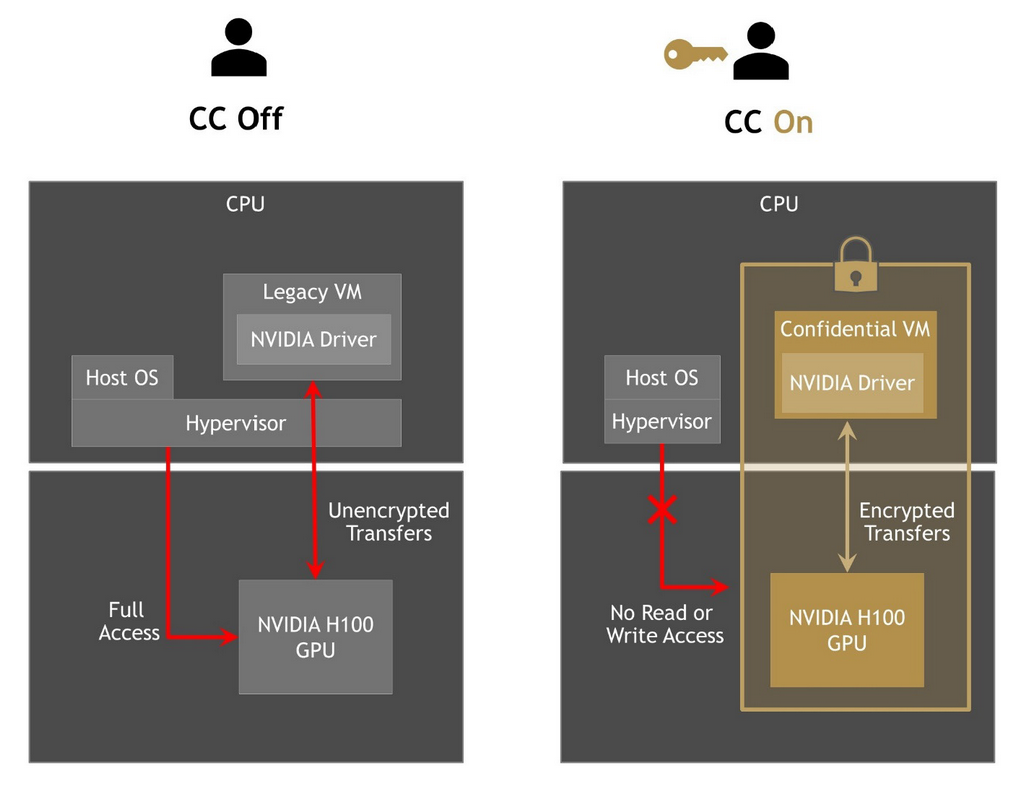
NVIDIA CC wyłączone vs. NVIDIA CC włączone. Izolacja maszyny wirtualnej
Pełna izolacja VM TEE i GPU TEE w celu utworzenia poufnego środowiska obliczeniowego jest zapewniona przez silne zabezpieczenia sprzętowe, w tym trzy kluczowe elementy, które częściowo wyjaśniono wcześniej:
- On-Die Root of Trust (RoT) — zanim system operacyjny będzie mógł komunikować się z GPU, GPU korzysta z RoT, aby upewnić się, że oprogramowanie układowe działające na urządzeniu jest autentyczne i nie zostało zmodyfikowane przez właściciela urządzenia (CSP itp.).
- Poświadczanie urządzeń — umożliwia użytkownikom upewnienie się, że komunikują się z autentycznymi procesorami graficznymi NVIDIA z włączoną funkcją poufnego przetwarzania, a stan zabezpieczeń procesora graficznego odpowiada znanemu, zaufanemu bezpiecznemu stanowi, w tym konfiguracji oprogramowania układowego i sprzętu.
- AES-GCM 256 – Transfery danych między procesorem a kartą graficzną H100 są szyfrowane/deszyfrowane z szybkością łącza PCIe przy użyciu sprzętowej implementacji AES256-GCM. Zapewnia to zarówno poufność, jak i integralność danych przesyłanych przez magistralę z kluczami dostępnymi wyłącznie dla procesora i procesora graficznego TEE. Implementacja kryptograficzna będzie certyfikowana zgodnie z FIPS 140-3 poziom 2.
Należy pamiętać, że do korzystania z technologii poufnych obliczeń firmy NVIDIA nie są wymagane żadne zmiany w kodzie aplikacji CUDA.